$5M grant will tackle pangenomics computing challenge
By: Eric Laine
The Panorama project aims to bring insight to computational pangenomics.
Sometimes to create a breakthrough, researchers need a problem complex enough to demand a fundamentally new approach. A team led by Christopher Batten, associate professor in the School of Electrical and Computer Engineering, found a truly big one: graph-based pangenomics.
As scientists continue to catalogue genomic variations in everything from plants to people, today's computers are struggling to provide the power needed to find the secrets hidden within mass amounts of genomic data.
Batten’s team is responding with the Panorama project, a five-year, $5 million NSF-funded effort to create the first integrated rack scale acceleration paradigm specifically for computational pangenomics.
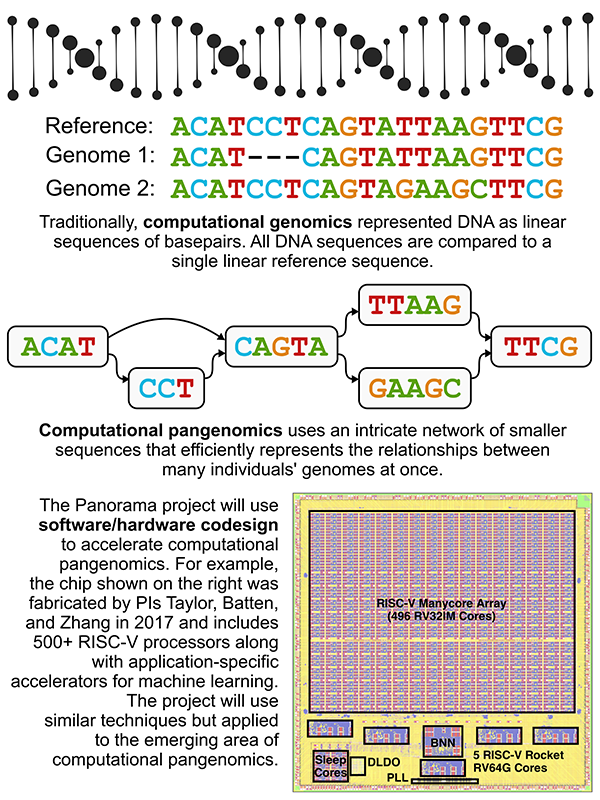
“The field of computational genomics is undergoing a sea change,” Batten said. The traditional method of examining DNA using a single linear reference genome is quickly giving way to a new paradigm using graph-based models that can address the sequence and variation in large collections of related genomes.
“With a single reference genome, you could understand other genomes as they relate to that single reference,” Batten said, “but it’s hard to understand how they relate to each other, and to everything else.”
More Than Big Data
Genetic researchers would be thrilled to investigate pangenome graphs that include millions of genomes, but for now it’s impossible. The computing power needed is just not available. The demands of graph-based pangenomics require rethinking the entire software/hardware stack. But this is not simply a “big data” problem.
“Yes, the data is big,” Batten explained, “because there is a lot of data. It’s also sparse because it’s irregular; not every sequence is the same and elements are missing. It’s dynamic because geneticists are adding newly sequenced genomes every day. And since each DNA sequence is unique to each person, we must keep it private.”
Building a computer system that can get answers from this big, sparse, dynamic, and private data set requires a collaborative approach from computer systems researchers working simultaneously on different layers of the stack.
“We need to rethink how we build computers,” Batten said. “That's why this project is so ambitious. In the past, you just waited two years and your computers would naturally become faster. But the slowing of Moore's law means that inevitable improvements in performance are just not occurring anymore. So you need a cross stack approach to really make an impact.”
That impact will take the shape of a prototype computer the team will design and build. Most laptop computers have four to ten cores, or central processing units. The Panorama prototype will have a million cores. The project’s vision for this powerful new computing tool is analogous to the impact of the Hubble Space Telescope: it will enable computational biologists to observe what was previously unobservable.
Recruiting an Interdisciplinary Team
The team Batten assembled to build this revolutionary system includes seven principal investigators from three universities with expertise in computational biology, programming languages and compilers, computer architecture, and security and privacy. The highly interdisciplinary team has a proven track-record of working and publishing together.
It started with a fortuitous meeting at an open-source software and hardware conference Batten attended in Belgium in January 2020 with longtime friend and research collaborator Michael Taylor, an associate professor of electrical and computer engineering at the University of Washington. There they connected with Pjotr Prins, one of the world’s leading researchers in computational genomics. Prins is an assistant professor at the University of Tennessee Health Science Center.
Together they realized the potential to make revolutionary advances in computing by focusing on the specialized domain of computational pangenomics, and its graphs of big, sparse, dynamic, and private data.
Prins brought in his UTHSC colleague, assistant professor Erik Garrison, a pioneer in the field of computational pangenomics. Batten also tapped resources from Cornell Engineering’s multidisciplinary Computer Systems Lab. Associate professor Zhiru Zhang (ECE) is an expert in hardware accelerators and efficient machine learning algorithms; professor Ed Suh (ECE) is focused on designing hardware to ensure the security of the entire computer system; and assistant professor Adrian Sampson (CS) specializes in programming languages and compilers.
“To unlock the full potential of pangenomics, we can't simply rely on traditional bioinformatics tools built to handle linear genome sequences,” said Zhang. His group will be investigating new graph learning algorithms, domain-specific programming models, and hardware accelerators. “We must develop new algorithms and hardware that can efficiently process the large and irregular pangenome graphs to effectively analyze many individuals' genomes at once and understand the intricate relationships between them.”
The Scale of the Problem
UTHSC currently works with a computer powerful enough to do a simple analysis across 60 people. It takes about a day. “If you double the number of individuals, the time will not double,” Prins told the Daily Memphian. “It will get even slower, maybe four times as slow.” Analyzing 1,000 people would probably take a month. “We want to be able to do it in minutes,” Prins said.
In pangenomics, the goal is not to understand a single individual; it’s to analyze the genomes of an entire population and study the relationships between individuals. Adrian Sampson, assistant professor in computer science, tried to explain the scale of the problem.
“Imagine sampling a thousand salmon from a given river to understand the biodiversity in that river,” Sampson said. “Researchers are also interested in the way each individual salmon differs from every other salmon. In a sample of 1,000 salmon, there are nearly 500,000 pairs of salmon to be compared to each other to understand the entire pangenome.”
Unlike data collected from other animal species, human DNA data is considered ultimately intimate and personal, in addition to being subject to strict regulation, and that’s why privacy and security are a major focus of the Panorama project. Ed Suh, professor of electrical and computer engineering, is an expert in computer hardware security.
“Rack-scale acceleration in the cloud promises to unlock a new level of computing capabilities,” said Suh. “However, security and privacy concerns often limit the amount or the type of data that we can bring into the cloud for processing.”
“A DNA sequence is arguably one of the most personal and private information a person has,” said Suh. “To fully leverage the potential of the rack-scale acceleration, our system needs to be able to provide strong assurance that sensitive and private data can only be used for specific purposes and cannot be stolen or altered by untrusted entities.”
Creating Potential
Sampson articulated the excitement shared by the entire team, that the Panorama project introduces totally new challenges in hardware design and programming. “We have an opportunity to generate specialized, single-purpose hardware that is really only capable of solving these enormous genomics problems,” he said. “This is not an easy task, but if we can achieve it, we’ll help biologists solve problems that they can’t even begin to approach with the computers they have today.”
The project’s name captures its holistic, cross-stack, software/hardware approach: a panorama is an unbroken view of the whole region surrounding an observer. The Panorama project outlines an ambitious set of research directions in the context of computational pangenomics, although the fundamental ideas will be broadly applicable across machine learning and graph processing.
The work will contribute to a growing resurgence in software/hardware co-design and demonstrate specific examples where it is effective to redefine traditional abstractions at the interfaces between the application, the programming language, the compiler, and the architecture. Ultimately, Panorama will enable computational biologists to better see the “genetic dark matter” which so far has been hidden, creating the potential for new scientific discoveries.